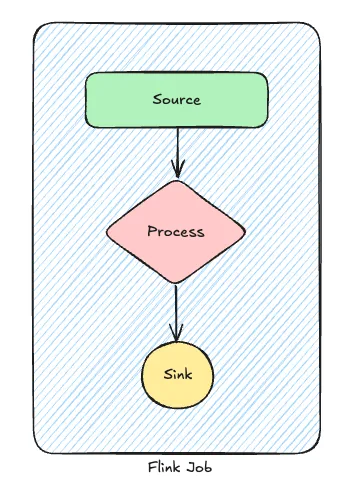
Flink's core architecture consists of:
- Source: Reads data from external systems
- Process: Transforms data using operators
- Sink: Outputs data to external systems
Supported languages: SQL, Java, Python

🔭 Building an Analytics Tool using Angular, NestJs, Java, Scala, Flink, MySQL & Snowflake ...
🌱 Currently learning Flink & AI/ML.
👯 Looking to collaborate on Angular, NestJs Open Source Projects.
🤔 Seeking help with AWS & Networking.
💬 Ask me about any tech-related stuff.
📫 Connect on Twitter: @saurabh47g
😄 Pronouns: He/His
⚡ Fun fact: NULL
🔗 GitHub: github.com/saurabh47
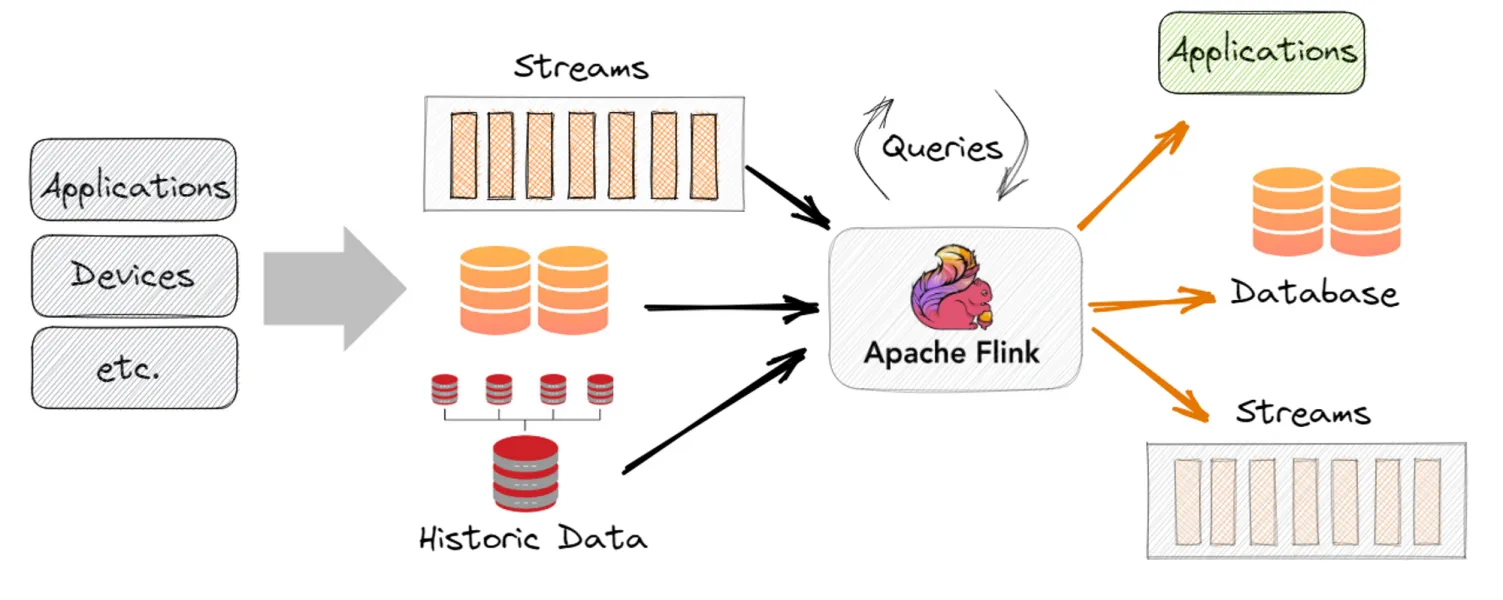
Introduction to Stream Processing
Apache Flink is a distributed stream processing framework for real-time and batch data processing.
Flink's core architecture consists of:
Supported languages: SQL, Java, Python

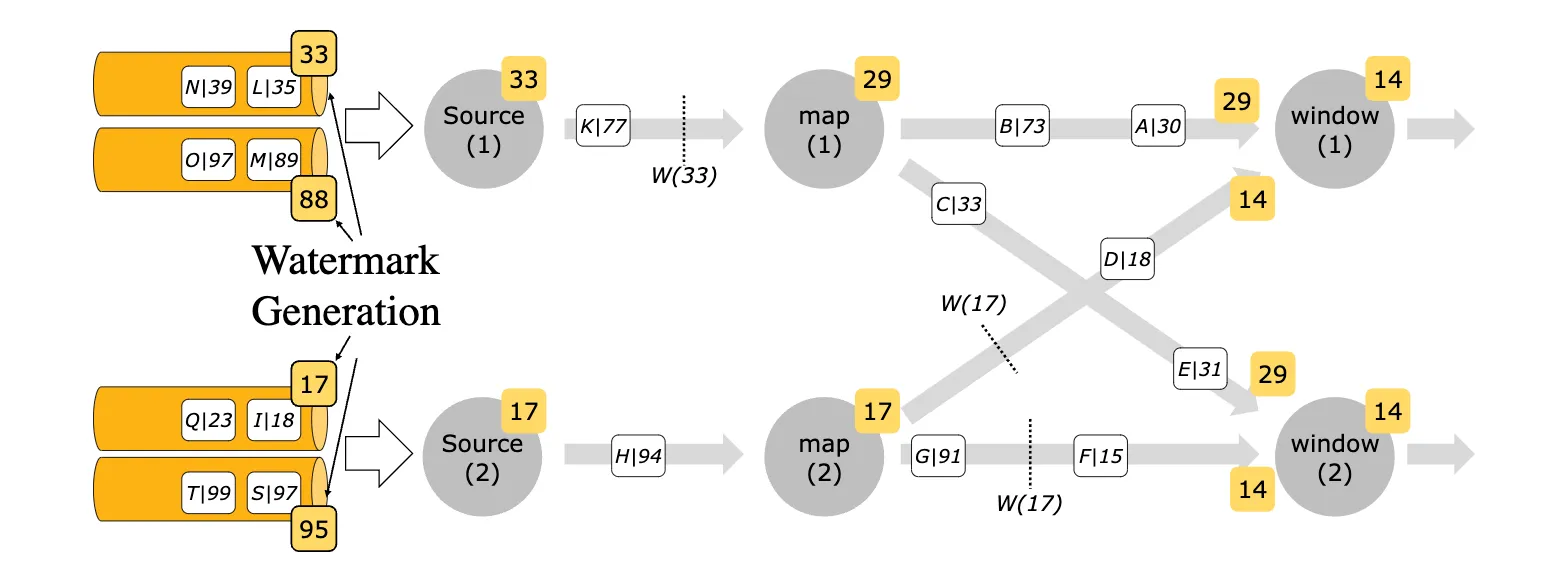
Watermarks help manage event time processing by tracking lateness.
Windows group data streams into finite sets for processing.



-- Source Table / Topic
CREATE TABLE sensor (
id STRING,
timestamp TIMESTAMP(3),
temperature DOUBLE,
WATERMARK FOR timestamp AS timestamp - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'sensor-data',
'format' = 'json',
'properties.bootstrap.servers' = 'localhost:9092'
);
-- Sink Table / Topic
CREATE TABLE aggregated_sensor (
id STRING,
window_start TIMESTAMP(3),
window_end TIMESTAMP(3),
avg_temp DOUBLE
) WITH (
'connector' = 'kafka',
'topic' = 'aggregated-sensor-data',
'format' = 'json',
'properties.bootstrap.servers' = 'localhost:9092'
);
INSERT INTO aggregated_sensor
SELECT id,
TUMBLE_START(timestamp, INTERVAL '10' SECOND) AS window_start,
TUMBLE_END(timestamp, INTERVAL '10' SECOND) AS window_end,
AVG(temperature) AS avg_temp
FROM sensor
GROUP BY id, TUMBLE(timestamp, INTERVAL '10' SECOND);